Hope you enjoyed my research notes so far, to organize the knowledge about analytic & data science in a more centralized way, I decide to start a new site, to make things well-structured so that shared knowledge will not be fade away with more blog adding.
Welcome to visit my new sites: www.magic-analytics.com
Wednesday, October 26, 2016
Thursday, March 3, 2016
Pandas and Spark DataFrame: structural difference
Pandas is a Python package for easy data manipulation and analysis. The basic data structure is based on NumPy array. It is very easy to see the trace of NumPy out of both series and data frame. The data should be able to fit into the memory to make it function.
Spark is a different language (or eco-system) designed for big data analytics. It's first popular data structure is the RDD (resilient distributed dataset), and then while its expanding into data science region, the concept of data frame is introduced (initially named as SchemaRDD, and changed into data frame after 1.3.0 version). So the Spark-DF is based on RDD, keep this in mind, then it is easy to understand why currently there are so many "seemingly easy" operations that not there yet.
(Note. Pandas version 0.17.1, Spark version 1.5.2)

Now based on above conceptual differences, easily some derivation on Spark-DF could be draw:
1. transpose Spark-DF would be very difficult (this is not what it is designed for)
2. adding new columns will need to change the schema (by adding a new field into the list), and created a new RDD to based on the original RDD and newly added RDD.
The list goes on and on, however, just keep one thing in mind, and then most of the difference in Spark-DF would be understandable: RDD is immutable, and it is designed for big data.
Spark is a different language (or eco-system) designed for big data analytics. It's first popular data structure is the RDD (resilient distributed dataset), and then while its expanding into data science region, the concept of data frame is introduced (initially named as SchemaRDD, and changed into data frame after 1.3.0 version). So the Spark-DF is based on RDD, keep this in mind, then it is easy to understand why currently there are so many "seemingly easy" operations that not there yet.
(Note. Pandas version 0.17.1, Spark version 1.5.2)
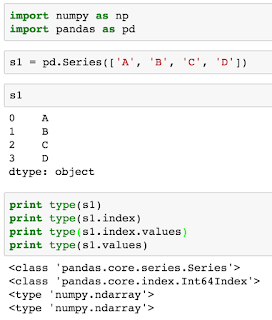
Basic data structures in Pandas
Two commonly used data structures are: Series and Data Frame.Series
Pandas series could be has index, and value, the index is a wrapper structure around numpy as its values attribute, series itself has values attribute, which is a numpy array as well. So basically, under the hood, two numpy arrays constructed one Pandas series.
Data Frame
Pandas data frame could be considered as two 1-D numpy array and one 2-D numpy array. It has attributes like: index, columns, values. With each as different wrapper over different sized numpy array. Thus it is easy to understand why doing transformation over pandas-DF is so straightforward: you just change the "index" into "columns" and "columns" into "index"!

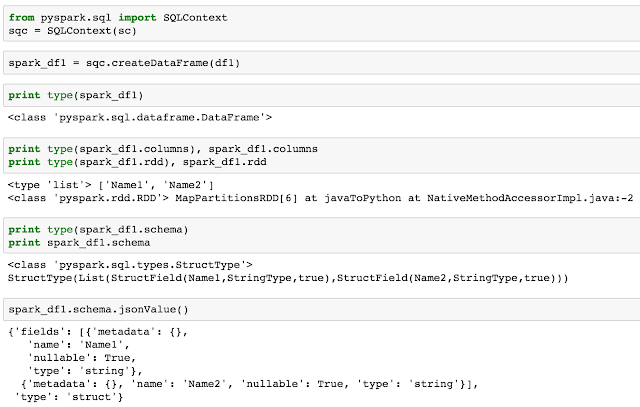
Basic data structures in Spark
RDD
(from Wikipedia): "...... resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way". In principle, the RDD is immutable, that means it can not be changed if constructed. Although it could undergo different transformations, and can be realized by action, the data inside RDD will not be change once it is initiated. Note. it only carry the data, not much meta-info is stored. The data scale is usually require multiple machines to parallel the storage and computation.
Data Frame
Spark-DF superimpose the schema over RDD, to make the RDD carry schema; from analytical point of view, it is easy to refer each column and dramatically facilitate data manipulations. While herein, there is no Numpy structure at all involved, everything is derived from the RDD concept and there is no index along the Spark-DF as well. There are three elements: RDD, schema, and columns (although there are lots stuff under the hood, for pure analytics purpose, this comprehension is sufficient)
Now based on above conceptual differences, easily some derivation on Spark-DF could be draw:
1. transpose Spark-DF would be very difficult (this is not what it is designed for)
2. adding new columns will need to change the schema (by adding a new field into the list), and created a new RDD to based on the original RDD and newly added RDD.
The list goes on and on, however, just keep one thing in mind, and then most of the difference in Spark-DF would be understandable: RDD is immutable, and it is designed for big data.
Wednesday, March 2, 2016
Pandas and Spark DataFrame
Spark DataFrame is a great way to do data analytics over big data, and it has many similar (not slightly different) APIs like the well-adopted python package: Pandas. Recently, I have been working with both of them quite frequently and I found it is very easy to misuse one with another.
Here are several great posts about the comparison between Pandas and Spark DF:
@chris_bour/6-differences-between-pandas-and-spark-dataframes
from-pandas-to-apache-sparks-dataframe
pandarize-spark-dataframes
Here are several great posts about the comparison between Pandas and Spark DF:
@chris_bour/6-differences-between-pandas-and-spark-dataframes
from-pandas-to-apache-sparks-dataframe
pandarize-spark-dataframes
Sunday, February 28, 2016
Elasticsearch with Python: document APIs
What is a document in ES: "In Elasticsearch, the term document has a specific meaning.
It refers to the top-level, or root object that is serialized into JSON and
stored in Elasticsearch under a unique ID."
If comparing ES with traditional SQL server, a document to ES is more like a row to SQL. It usually represent one object stored in ES's index.
There are quite a few handy commands in elasticsearch-py to do following operations:

or one can specify the op_type as "create", with the only difference that if the "id" already exist in the index, the operation with "create" will return error, while the operation with default ("index") will simply update the document.




If comparing ES with traditional SQL server, a document to ES is more like a row to SQL. It usually represent one object stored in ES's index.
There are quite a few handy commands in elasticsearch-py to do following operations:
Insert/update single document into an index

or one can specify the op_type as "create", with the only difference that if the "id" already exist in the index, the operation with "create" will return error, while the operation with default ("index") will simply update the document.

Delete single document from an index
Insert/update/delete multiple document(s) into an index
This is more involving than a single document operation. This require to load the "helpers" module, and pass the "es" and a list of "actions" into the "helpers" object.

Then we may want to access to different documents. Accessing different documents is not exactly same as doing a search, because one need to know its index, type and id. So it would be nice to put it here before going deep into search.
Access documents from an index

{kind=link}
Elasticsearch with Python: introduction
Elasticsearch (ES) is a search server based on Lucene.
Currently it has been widely used in different products to provide near
real-time search capacity. As a Python user focusing on analytics, having ES
integrated with existing Python experience would be mostly helpful &
convenient. Recently, I found the following two official ES client quite
useful:
Preparation
Step 2: install python analytics packages (iPython Notebook,
pip install elasticsearch-py and elasticsearch-dsl), then open the iPython
Notebook (or called Jupyter notebook now)
Step 3: set up the connection between the iPython notebook
with your local server.
from elasticsearch import Elasticsearch
es = Elasticsearch('localhost:9200')
That's it! Now the "es" variable refers to the
elastic search instance you just initiated.
Explore ES Client
Step 1.: install ES on local machine to start the game.
(version: 1.7.5) After download the package, unzip it, and then run
"./bin/elasticsearch", a new ES server will be started. By default,
the url to access is "localhost:9200"
The mostly used one (beside es itself) is the es.indices,
since it includes all operations about the index.

Index Operation
The index operation includes: create, display, and delete.
Those operations are shown below:

Sunday, June 8, 2014
Python: "in" for List v.s. Set
Both list and set are two basic data structures in Python, and they are widely used. Both data structures support the "in" statement, so either ' a in one_list: ' or ' a in one_set' is legit. However, the simulation speed differs dramatically and I will illustrate this finding with one example.



This example is a very simple options which use "not in" multiple times, from 1000, to 10000, to 100000, which mimic the 10 fold increase over N. The simulation time, for using list structure, requires almost N^2 times, while for set structure, requires almost N times.
This suggest the "not in" operation in set is much more advantageous than the list.
Subscribe to:
Comments (Atom)